

Building a scalable machine learning solution takes a lot of up-front solution architecture. It’s easy to process more and more data, but how do you do that while still providing relevant insights to an ever-growing group of individual users with each having a unique set of needs and challenges?
It helps to break down the data into different buckets to better understand it. To oversimplify it, we can assign data to 3 different groups:
- Key variables (factors) that affect the outcome
- Supporting data (often, time-series data)
- Noise
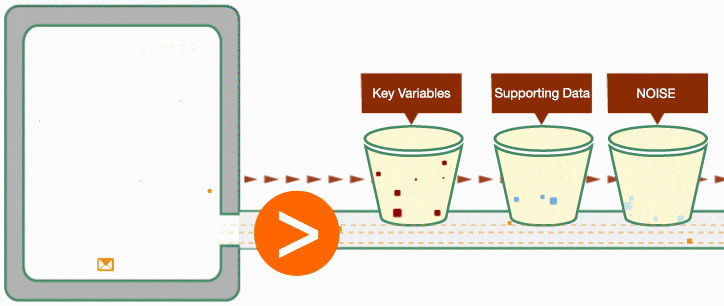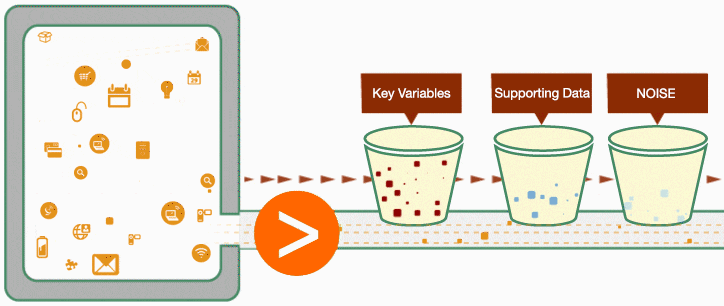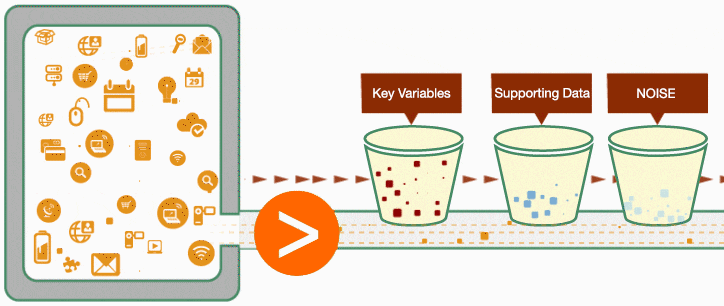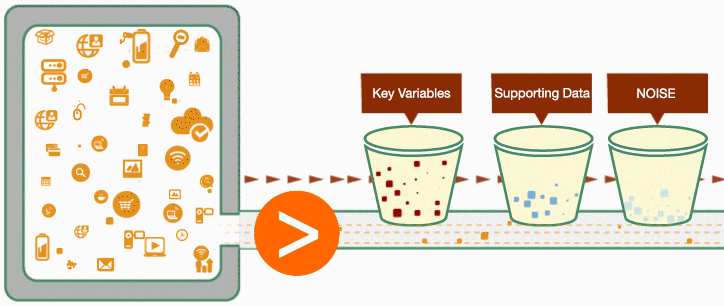
Data Scientist can build an initial model considering all the known variables that are known to influence the outcome. The obvious challenge here is to correctly assign weights (importance) of each variable on the results. That is when the statistical and mathematical expertise plays a critical role.
Each variable we considered consists either of static or dynamic data points. For example, if our model considered weather then we need to continually update the data in the model to keep the results accurate. We can do that with the help of APIs and IoT devices; we talked about that in “Think in Real-Time” article. Static data doesn’t change as often, for that reason we don’t need to update it that frequently and it can be updated manually. For example, when a company acquires a new plane for its fleet, the specifications for the new aircraft are needed to be added to the database only one time, unless those specs change consistently.
The other challenge is that importance (weights) of variables is continuously changing depending on many different attributes. Making the model adaptable to all situations is extremely hard and often requires local expertise. The same asset utilization model might do wonders in one company and might be completely useless in another.
To mitigate these risks, one can make models transparent so that the decision makers, who are dependent on the outcomes of such models, could identify and modify the inputs and the rules to make the model consider their unique challenges and opportunities. Building machine learning applications as black box solutions that only data scientists understand can become extremely expensive to create and are prone to breaking down due to their complexity.
Now, that we considered all the available structured data, there is a larger bucket of unstructured data. Dealing with that can make previous steps seem easy.

There are many steps that one can take to turn noisy unstructured data into actionable insights. Starting with statistical analysis to reveal patterns. If you are an Amazon or Google, then statistical models might be more than enough to generate additional billions in revenue. Unfortunately, for many other enterprises, these models might only reveal general insights already known to the employees. In which case a machine learning application needs to have a large number of training sets to teach it what to look for in the noise of Big Data.
Data Scientists can spend up to 80% of their time creating training sets and cleaning up data in the pre-processing stage. That is something that business leaders are not considering when they are committing to building out data-driven applications.

Accuracy rate is another major hurdle that is often not considered when these projects start. The more noise one introduces, and the more complex the model gets, the lower the accuracy will be (when it comes to unstructured data).
To improve the accuracy beyond statistical analysis, data scientists would often rely on Subject Matter Experts (SMEs, sometimes referred to as Domain Experts) to enhance the understanding of the relationship between data. That can significantly slow down the learning process since domain experts need to teach data scientists and data scientists need to train the model.
The existing machine learning iteration cycle looks like this:
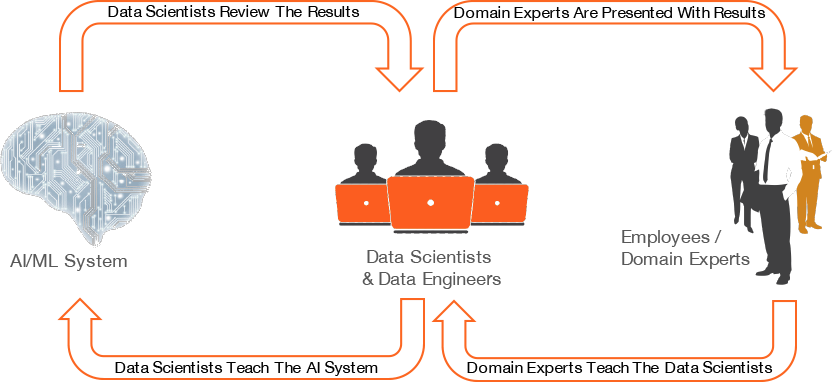
At Logyc, we re-designed this process. By adding a human-augmentation layer to machine learning, the system can identify when there are unknown variables that affect the outcome, discover individuals with the most relevant expertise within the company and learn directly from them. Then the system runs simulations with the new data to verify the accuracy of the information. If new variables, in fact, do affect the outcome then the new variable will be added to the model, the supporting data will be connected to the model, leading to the improvements in the accuracy of the results.
Logyc’s Human-Augmented Machine Learning Cycle:

Better results are essential, but it is also important to note how quickly the system can learn. The goal of Logyc’s platform is to accelerate cumulative knowledge gathering within the enterprise. Many enterprises have more than 100 employees (Subject Matter Experts within their role at the company) for every 1 Data Scientist they hire. That makes it very challenging for a data scientist to learn from the implied expertise help within the enterprise. Logyc changes that!
